Fantasy Tour dé France
A fun project scraping and trying to build the historically best Fantasy Tour dé France team.
Presentation
github src
Rules
- Pick (exactly) 9 riders
- Each rider costs a fixed number of points
- Team must cost <= 100 points
- Must pick 2 All-Rounders, 2 Climbers, 1 Sprinter, 3 Unclassed Riders and 1 Wild Card
- No team changes/substitutions after Tour starts
- Scoring is based on stages and various other points each rider can collect along the course of the race
- The winning (fantasy) team is not necessarily composed of the riders who came 1st-9th.
- https://www.velogames.com/tour-de-france/2017/rules.php
Goals
- Come up with 3-4 team suggestions
- Secretly enter the fantasy league
- …..
- Bragging rights
Collecting the Data
Gather Rider Data
- Data to Collect
- For every available rider choice in 2017:
- Previous year(s) costs, scores and categories
- 2017 cost and category
- For every available rider choice in 2017:
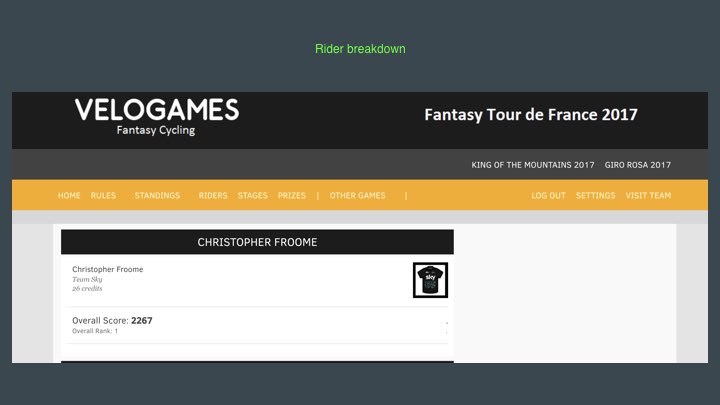
Riders Breakdown
Christopher Froome | Team Sky | 26 Points
Richie Porte | BMC Racing Team | 22 Points
….
191 Total Riders
Data Gathering Complications
- Each rider’s cost and past performance live in separate web pages
- Previous year web pages are in different formats
- Some pages are behind a login (cookie/auth issues)
Data Gathering Solution
br = mechanize.Browser()
# ignore robots.txt
br.set_handle_robots(False)
# pretend to be mozilla
br.addheaders = [("User-agent","Mozilla/5.0")]
# get the markup for the all players page
response = br.open(all_players)
assert response.code == 200
# get all the links for each players page
soup = BeautifulSoup(response.read(), 'html.parser')
player_links = [(link.get('href'),link.getText()) for link in soup.find_all('a') if 'riderprofile.php' in link.get('href')]
# go to each players page and retreive all the stage stats
for (player_link, player_name) in player_links:
response = br.open(player_base + player_link)
soup = BeautifulSoup(response.read(), 'html.parser')
for tr in soup.find_all('tr'):
row = player_name + ',' + year + ','
for td in tr.find_all('td'):
row += td.getText().strip('\r\n') + ','
print row.encode('ascii', 'ignore')
Final Raw Datasets
velobet (master) $ head player_2017.csv.bak | column -s ',' -t
Category Cost Name Team
All Rounder 1 26 Christopher Froome Team Sky
All Rounder 1 22 Richie Porte BMC Racing Team
All Rounder 1 16 Alberto Contador Trek - Segafredo
All Rounder 1 16 Alejandro Valverde Movistar Team
All Rounder 1 14 Thibaut Pinot FDJ
All Rounder 1 12 Geraint Thomas Team Sky
All Rounder 1 10 Andrey Amador Movistar Team
All Rounder 1 10 Ion Izagirre Bahrain Merida Pro Cycling Team
All Rounder 1 10 Diego Ulissi UAE Team Emirates
...
velobet (master) $ head player_2014.csv.bak | column -s ',' -t
PlayerName Year Stage STG GC PC KOM SPR SUM BKY ASS Total
Vincenzo Nibali 2014 Stage 1 - - - - - - - - 0
Vincenzo Nibali 2014 Stage 2 150 25 2 - - - - 4 181
Vincenzo Nibali 2014 Stage 3 - 25 - - - - - 4 29
Vincenzo Nibali 2014 Stage 4 - 25 - - - - - 4 29
Vincenzo Nibali 2014 Stage 5 100 25 2 - - - - 14 141
Vincenzo Nibali 2014 Stage 6 - 25 - - - - - 10 35
Vincenzo Nibali 2014 Stage 7 - 25 - - - - - 10 35
Vincenzo Nibali 2014 Stage 8 100 25 - - - - - 10 135
Vincenzo Nibali 2014 Stage 9 - 22 - - - - - 6 28
...
Build the Model
- Look at all the possible team combinations in the past that
- cost <= 100 points
- satisfy the category requirements
- For each team_combination
- compute the final score the team would have scored in that year
- Choose the historically highest scoring teams for each year
Dataset Size
wc -l cost_combinations.csv
1530652 cost_combinations.csv
There are ~1.5 Million combinations of costs that total <= 100 points. Combined with 191 Players, this is around ~400 Billion potential teams combinations to sort through.
Model v2
The same model idea - optimize the number of teams to sort through by reducing the total number of combinations.
Start with a cost combo
26,16,4,6,4,4,8,8,4,80
This is a combination of costs that is <= 100 points and satisfies the category requirements (each column is the required category - last column is total of the columns to the left).
Pairing down
- With the current cost combo
(26,16,4,6,4,4,8,8,4,80)- Produce all player combinations that match that cost
- Multiple players can have the same cost (use python set() ‘s to collect unique combinations) use the python yield construct for faster performance
- From the given potential players, choose the highest scoring players - create a team with these players.
- Produce all player combinations that match that cost
for combo in bucket_combo(best_avail_players):
sc = set(combo)
if len(combo) != len(sc):
continue
yield combo
def bucket_combo(l, depth=0) :
''' return all combinations of items in buckets '''
for item in l[0] :
if len(l) > 1 :
for result in bucket_combo(l[1:], depth+1) :
yield [item,] + result
else :
yield [item,]
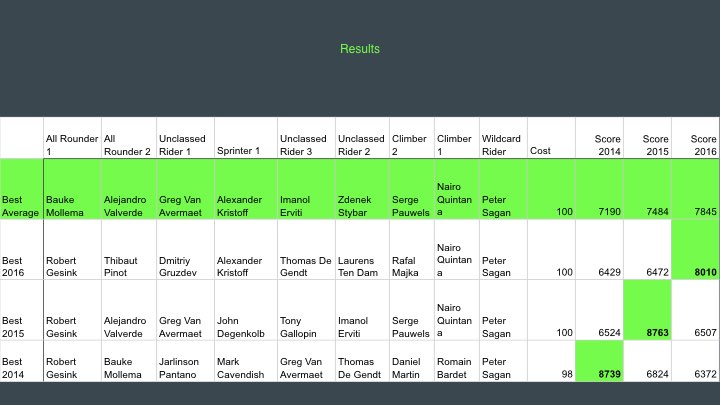
Model Optimization Results
- Tweaking the algorithm results in
- Load all
1.5M cost combinationsinto an indexed map: ~30s - Generate the best team for each cost combination for each year individually, and average for all 3 years:
- ~180s*
- Load all
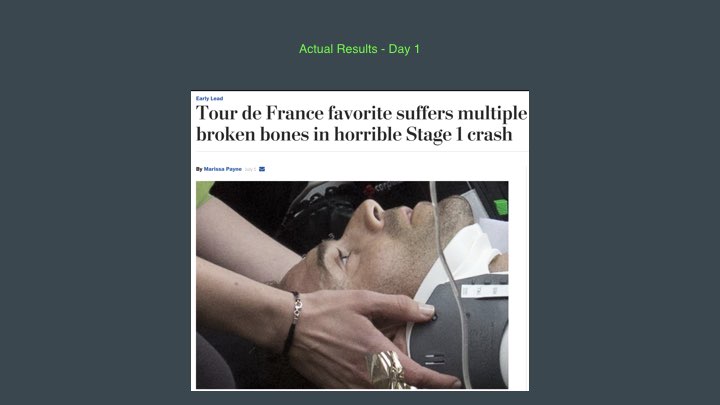
Actual Results Day 1
Actual Results Day 3


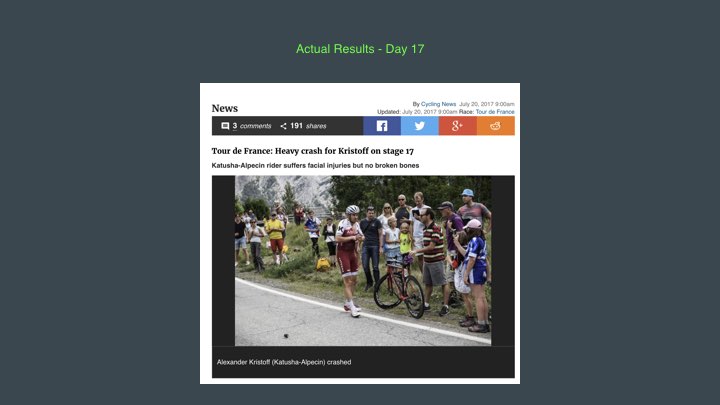
Actual Results Day 17
Final Results
- 15th place
- Out of 19.